Web Crawler
- Design a web crawler
- Design thread-safe producer and consumer
- Design Typeahead
4S分析
- Scenario: How many web pages? how long? how large?
- Service: Crawler, TaskService, StorageService
- Storage: Use db to store tasks, BigTable to store web pages
Simplistic News Crawler
- urlopen, get the plain text
- use regular express to get the header
- use regular expression to get all the links and then add them all to the URL queue
//thread crawler
function run
while (url_queue not empty)
url = url_queue.dequeue()
html = web_page_loader.load(url) // consume
url_list = url_extractor.extract(html) //produce
url_queue.enqueue_all(url_list)
end
- 当两头速度不一样的时候,需要buffer在中间,这样就构成了producer consumer模型
- single thread, too slow
Multi-Thread
- resource conflicts,一个在读一个在写
- 3 approaches:
- sleep:
- condition variable
- semaphore 只允许一定数量的threads同时写一个资源
- 局限,不是越多线程就一定越好
- context switch cost (CPU limitation 例如单个线程里每一秒切成十份分别去执行,上下文切换)
- thread(port) number limitation (TCPIP的端口是有限的)
- network bottleneck for single machine (带宽的限制)
多机器Multi-Thread
有可能遇到URL queue太大,无法存到内存中的问题。所以把URL queue放入数据库中。
| id | url | state | priority | available_time | |
|---|---|---|---|---|---|
- state: 因为每个crawler可以一次要多条(以节省数据库的read请求),这时候就能标记working
- priority: 每个网站的信息量不同
- available time: 下一次抓取时间,因为每个网站的更新频率不同,可以动态更新。
Handle Issues
Slow Selector
Task Table (url db)很大的时候,select会很慢(而且还要根据priority,available来排序和选择)
- 分布式的db,由一个scheduler来分配到每台机器
Update for failure
后一次抓取的结果跟前一次不同。
- Exponential back-off
- 遇到更新(不同),则不断的把抓取间隔减半,(1/2, 1/4, 1/8...),这样直到时间一致
- 如果遇到抓取失败(网页失效),则把抓取时间加倍,(2, 4, 8, ...),知道发现网页彻底失效
Dead Cycle
sina.com里的urls有很多的sina.com,就陷入了一个循环,不断在再重复
- 发现在某个时间点,有很多个sina,可以为这个网站设定一个限额。
Scale总结 single -> multi, multi -> distributed, queue -> table, slow select (db sharding), craw failure/update handle, dead cyle(sina.com -> quota), multi-region
Typeahead
Google Suggestion
- Scenario: prefix -> top n search keywords
- DAU: 500m
- Search: 4 (敲四个字符) 6 500m = 12b
- QPS = 12b / 86400 = 138k
- Peak QPS = 2 * QPS = 276k
Service:
- QueryService
- DataCollectionService
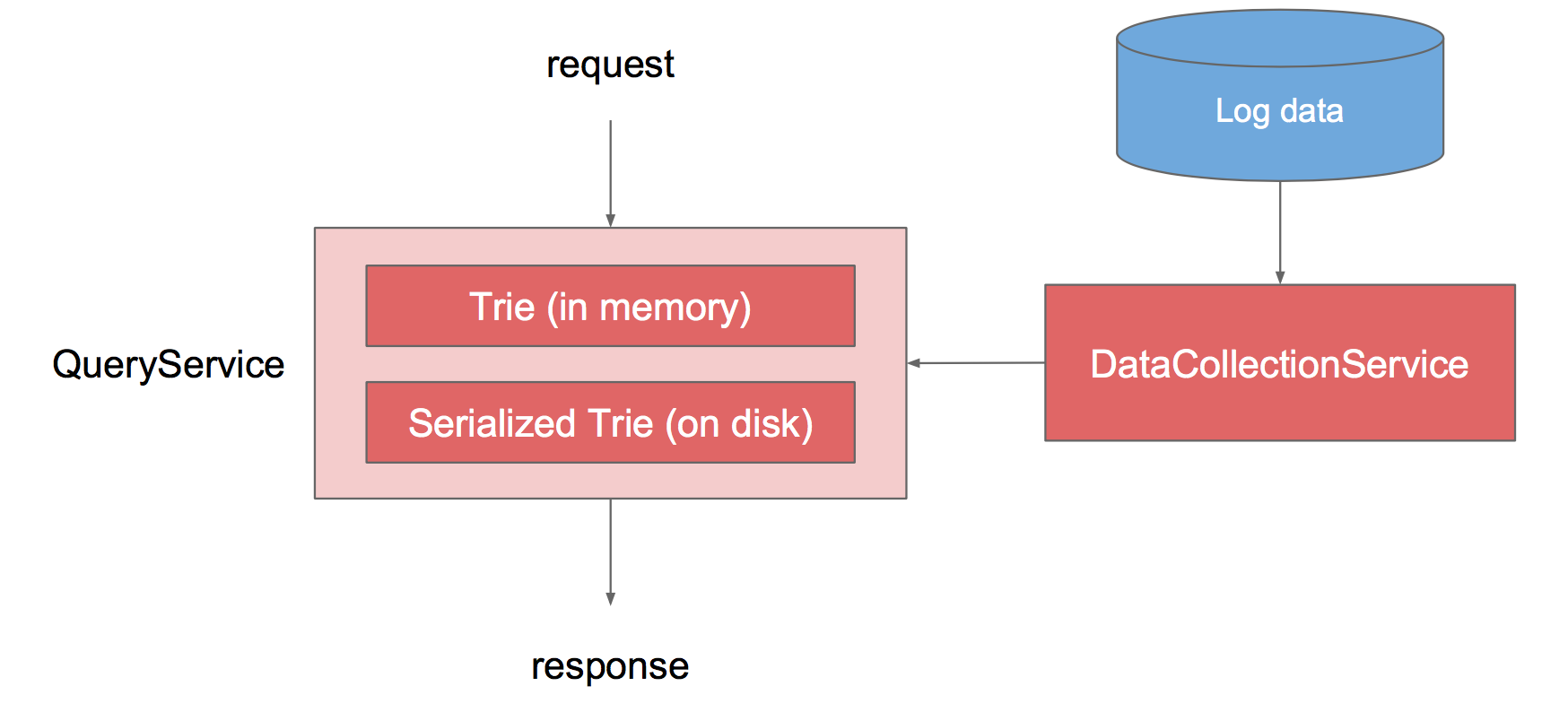
- Storage
- QuerySerivce
- naive way,保存keyword和hit_count
- 但是需要用SQL like语句,效率很低(等价于key>='abc' and key<= 'abd')
- 把刚才的数据表进行转换,转换成prefix和keywords。
- 例如prefix=a, keywords=["amazon","apple",...]即keywords直接为想要的结果
- 转化过程中,不仅保存"amazon",也保存他的hit_count,这样当keywords满了以后,才可以决定要保留那些
- trie
- 每个char是一个节点,每个节点保存到这里构成的单词的count
- 每一次查找的复杂度为O(26^h),h是这个点的最高子树高度
- 持久化到硬盘,只有启动的时候加载入内存
- 再进一步优化,在每个节点上保存的是以这个节点为prefix的top 10
- 转化过程中,每个前缀节点,都加入当前的keyword及其count。例如apple,a,p,p..都要保存apple:15b
- 不需要用PQ,只需要插入排序维护即可
- naive way,保存keyword和hit_count
- DataCollectionService
- log data (user, keyword, timestamp)
- mapreducer 统计,group by keyword
- how often? QueryService和DataCollectionService的协同工作。有两个queryserive,一个live,一个offline,等offline更新了以后,再跟live service switch
- QuerySerivce
- Scale
- reduce response time in front-end (browser)
- browser cache
- 比如da,回删得到d,此时就不需要重新再请求d
- 不止返回前10个,比如1k个,下一个词有很大概率在这个top 1k中,那么直接就可以返回。
- browser cache
- what if the trie gets too large for one machine
- store one trie to multiple machines
- 问题:要在哪一台机器里找?-> 把char转化成一个int,然后mod机器个数。这样就可以有
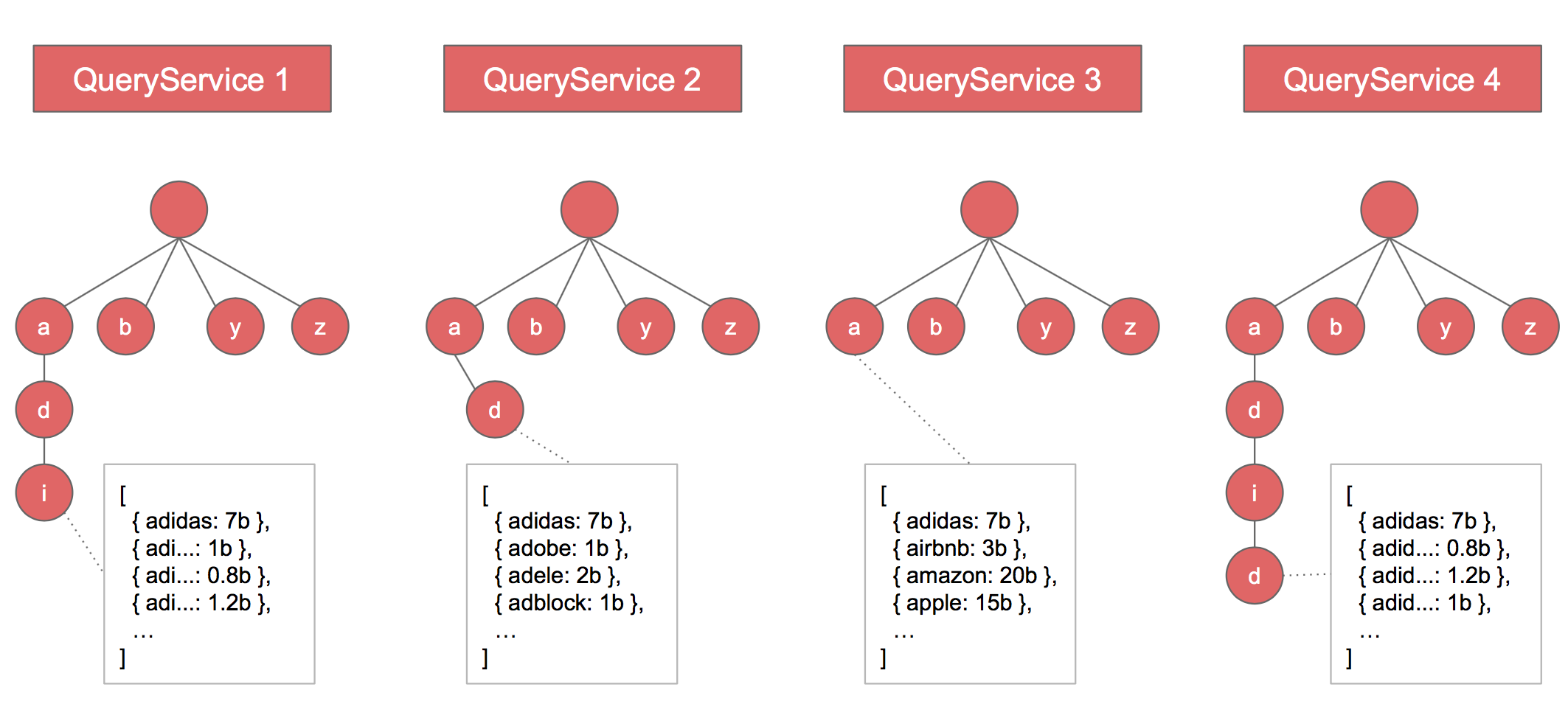
- 这样每个前缀所需要保存的数组,对应在不同的机器,这样每个机器就比较少。这样用户查找和更新的时候都可以很容找到
- 警惕问题:不能以字母开头来划分分布式,这样会存在bias,必须用上面的consistent hashing来保证分部均匀且能存的下
- 问题:要在哪一台机器里找?-> 把char转化成一个int,然后mod机器个数。这样就可以有
- store one trie to multiple machines
- how to reduce the size of the log file
- 并不是当每个用户搜索时候存下次数。而是用probability来记录log,例如搜了1k次Amazon才记录一次 Probabilistic logging
- reduce response time in front-end (browser)