Design User System
Scenario 场景
- 注册、登录、查询、用户信息修改 ,哪个需求量最大?
- 支持 100M DAU
- 注册,登录,信息修改 QPS约
- 平均每个用户每天登录+注册+信息修改0.1次,100M * 0.1 / 86400 ~ 100
- Peak = 100 * 3 = 300
- 查询的QPS
- 平均每个用户每天与查询用户信息相关的操作次数(查看好友,发信息,更新消息主页) 约为100次
- 100 M * 100 / 86400 ~ 100k
- Peak = 100k * 3 = 300 k
Choose DB based on QPS
- MySQL / PosgreSQL 等 SQL 数据库的性能 1k
- MongoDB / Cassandra 等 硬盘型NoSQL 数据库的性能 10k
- Redis / Memcached 等 内存型NoSQL 数据库的性能 100k~1m
Storage
拿到题目的第一个思考点是考虑,读和写哪个比较多。而用户系统是典型的读远远多于写的系统。所以一定要用Cache
Cache
- 类似于Hashmap,由key-value结构来取。保存在内存里,
- 常用的包括
- Memcached 断电会丢失数据,是cache aside类型的,即server分别与cache和DB沟通
- Redis 支持数据持久化,读写都比较快(可以理解为Redis里包含了一个cache和一个DB,是cache trough类型的,服务器只和cache沟通,cache负责和DB去沟通,把数据持久化)
- Cache不一定是在内存中,可能在文件系统,同时client side也能够有客户端
- 数据may be evicted by cached,所以要expect不存在
access pattern
- write through cache
- 同时写cache和DB,只有二者都写成功了,才视为write完成。
- latency比较高,适用于write and re-read很快的系统
- Write around cache
- 直接写到DB,然后cache从db里读取信息,这样使得write变快,但是read latency变高
- Write back cache
- write直接在cache层面完成,然后在async的同步到db中。
- 由于cache is non-persistent,有可能丢失数据(可以引入replica)
availability vs consistency
Cache如果unavailable了,必须去通过db读取,会导致严重的latency并给DB带来load,而事实上,在读取数据的时候,(例如这里的timeline),可以允许有一些最近的数据不是立即显示,可以在reasonable的一段时间后显示
Set时候的操作
cache.delete(key)
db.set(user)
必须要考虑出现Fail的状况
cache.set(key, user)
//DB fail
db.set(user) //fail
此时cache和db的数据不一致,下一次get的时候就是cache的脏数据
cache.delete(key)
//DB fail
db.set(user) //fail
这种情况不会出现数据不一致,只是cache里被删除了key。下次需要重新load。用户会收到修改信息失败的提示,用户自己可以选择再点一次“保存”进行重试
Muti-threads LRU
- HashMap + DLL
- read:
- peration 1 : A read from the HashMap and then,
- Operation 2 : An update in the doubly LinkedList
- write
- Operation 3: Figure out the least recently used item from the linkedList
- Operation 4: Remove it from the hashMap
- Operation 5: Remove the entry from the linkedList.
- Operation 6: Insert the new item in the hashMap
- Operation 7: Insert the new item in the linkedList.
- 对于读的部分,map必须要立刻更新,而DLL可以async的;对于写的部分,client不需要反馈,所以后端的这些操作都可以是async的,所以从这个角度来说只需要对Op1加read lock,op4和6加write lock
- 进一步细分,考虑到HashMap的实现,这里用hashing with linked list,所以可以在每一行上创建lock,这样只要读写不在hashmap的同一行,则不会互相影响
- read:
以Cassandra为例分析NoSQL
与SQL不同
- 不再是以row为单位,而是以grid为单位(row_key, col_key, value)
- 不需要提前定义schema,只需要提前规定好每个值的格式
三层结构
- row_key: key-value中的key,存在于那一个实体机器上。方便做sharding,e.g user_id
- col_key: 是排序的,可以进行range query。可以是一个复合值。比如一个timestamp+user_id. row_key和col_key加起来构成了真正的key。用以进行range query
- value: 一般是string,如果要多余信息的话,自己做serialization
例如存储好有关系时候,如下 1和2是好友,2和3是好友
| row_key | col_key | value |
|---|---|---|
| 1 | 2 | null |
| 1 | 2 | null |
| 2 | 3 | null |
| 3 | 2 | null |
Service 服务
一个 AuthService 负责登录注册
Session
一个session table
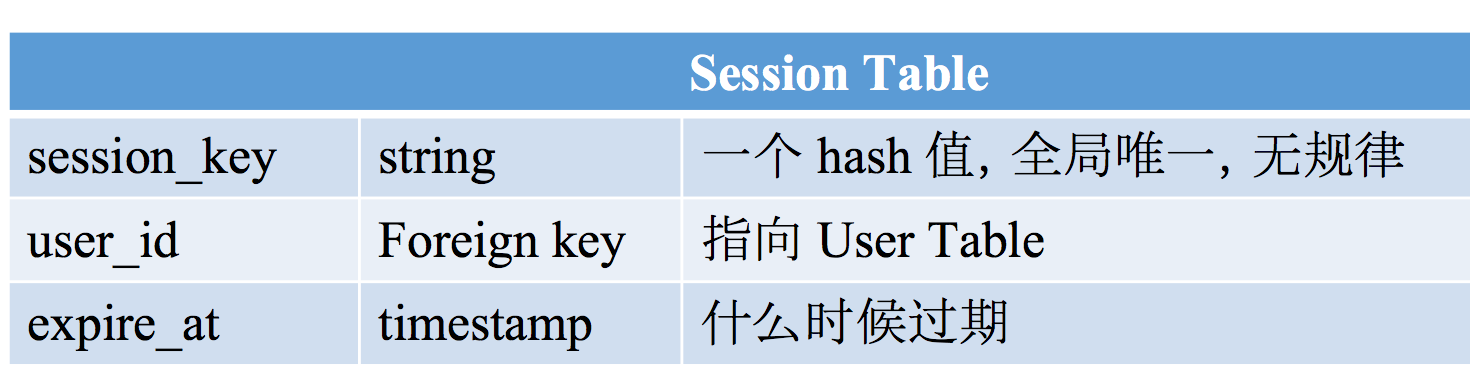
创建一个session对象,并把session_key作为cookie值范围给浏览器,浏览器将该值记录在浏览器的cookie中。每次用户向server发送request,都会带上cookie,此时服务器检测cookie中的session_key是valid的
- 用户Logout之后,从session table里删除数据
- session table可以保存在数据库或者缓存
- 但是如果存在cache里中,断电以后即所有用户就都logout了,可能会短时间内造成非常大量的login
一个 UserService 负责用户信息存储与查询
- 一个 FriendshipService 负责好友关系存储
- 单向好友关系,friendship table保存from_user_id和to_user_id
- 双向好有关系
- 存为两条信息,A关注了B,B关注了A
- 存为一条信息,但是查询的时候需要查两次
- 好友有关系设计的操作都是key-value型的:
- 求某个user的所有关注对象
- 求某个user的所有粉丝
- A关注B -> 插入一条数据
- A取关B -> 删除一条数据
- 选择数据库的选择
- 需要支持transaction的话不能用NoSQL (转钱,两个操作需要同时成功或者同时失败)
- NoSQL需要自己Serialization
双向好友关系
- 存一份,用smaller_user_id和bigger_user_id,用两个select语句
- 存两份,每次保存from_user_id, to_user_id
Scale
Sharding
- 按照一定规则,按照数据拆分成不同的部分,分别保存在不同的机器上
- 这样就算挂也不会保证网站完全不可用
- SQL不自带sharding
- NoSQL就是为了sharding而设计的
vertical sharding
- 每个表table放在不同的数据库
- 还可以将一个table中拆成两个table
- 例如user table中的email,pw等不经常改变,而别的fields经常变化,则可以拆成两个表user table, user profile table这样如果user table挂了也不影响登录
- 但是当这个table仍然很大的时候,还是无能为力
horizontal sharding
- naive 直接平均(mod10)后放到10个数据库里
- 不可行,当有新的机器加入,几乎所有的数据都要迁移。迁移期间,server压力增大,有可能不一致
Replica
- 一式三份,一般有两个备份存储的比较近,第三个备份存储的比较远。
- 同时还能分摊Read requests