Design an Uber
Scenario
- phase 1
- Driver report location
- Rider request uber, match a driver with a rider
- phase 2
- driver deny / accept a request
- driver cancel a matched request
- rider cancel a request
- driver pick up a rider / start a trip
- driver drop off a rider / end a trip
phase 3
- uber pool
- uber eat
假设200k司机同时在线
- driver QPS = 200k / 4 = 50 k
- report location every 4s
- peak QPS 50k * 3 = 150k
- rider QPS 可以忽略,因为只有请求时候需要,远小于driver的
- driver QPS = 200k / 4 = 50 k
- 存储数据的估算
- 记录每条location: 200k 86400 / 4 100 bytest(每条位置记录) ~ 0.5T/day
- 记录当前位置信息: 200k * 100bytest = 20M
Service
- GeoService 记录位置
- DispatchService 匹配打车请求
report location的同时,服务器顺便返回匹配上的打车请求
//Trip Table写的时候只有user request的时候写,而每次司机report location的时候,都顺便读一下
class Trip {
tripId,
driverId, riderId,
latitude, longitude,
status,
CreatedAt
}
class Location {
driverId,
latitude, longitude,
updatedAt
}
Storage
难点:如何存储和查询地理信息?
- 如果直接用select+where的range query,那么操作就会非常慢,等同于扫了一整遍数据
Google S2
将地址空间映射到2^64的整数,如果空间上比较接近的点,对应的整数也比较接近,一种逼近的思路,更精准,库比较丰富
Geohash
用字符串来带对应地理位置,把地图不断的细分为32个小格子
- 字符串为Base32: 0-9, a-z去掉(ailo)
- 公共前缀越长,两个点越接近
先经后纬,交替二分,在左半边记为0,右半边记为1;对纬度,下半部记0,上半部记1。最后得到了一定长度的数据,每五个数字可以转化成上边base32中的一个字符
根据误差表,可以确定,当前几位相同的时候,误差大概在什么范围之内。所以当要找到附近的车,则就去找精度误差>2公里 对应的string的最长长度
- Use SQL
- 所以在Location Table中,多保存一个geogash,并且以此为index。
- query时候用like query即可
- 可以用,但是慢,因为like query叫慢。同时driver需要经常update位置,index col就需要被经常修改,不合适
- NoSQL - Cassandra
- 把geohash设为col key
- 使用range query
- 问题类似于SQL,col key index经常被修改,不合适
- NoSQL - redis/memcached
- 把driver的位置分级存储,例如9q9hvt,则存储在9q9hvt,9q9hv, 9q9h这三个key中,value即为一个set of drivers in the locatio
- 因为6位geohash的精度已经在一公里以内,对于uber类应用足够,4位精度已经在20公里以上了,再大就没有意义了
- Memcachedn没有持久化,并且不支持原生的set结构
结论:Redis最合适
- 数据可以持久化
- 原生支持list, set等结构
- 读写速度很快,接近内存速度 > 100k
用户角度
发出打车请求User(lat, lng)->geohash->从lacation table里获取周围的driver_id set
- 搜索的时候,先查6位的geohash(0.6公里)
- 若找不到,再查5位,(2.4公里)
- 然后4位 (20km)
匹配成功后,根据driver_id,查询driver的具体位置 driver_id->(lat, lng)
司机的角度
- 司机汇报自己的位置
- 计算当前位置的geohash (geohash4, geohash5, geohash6)
- 查询原来所在的位置,对比是否发生变化,并且将变化的部分在redis中修改,通常来说只有geohash6比较经常变,所以QPS不会变化太多
- 在driver table更新自己的活跃信息
- 司机接受打车请求
- 修改trip状态。(用户在发出请求的时候,就已经在trip table中创建了一次trip并且match上了司机)
- driver table中更新自己的状态
- 完成接送
- 修改trip状态
- 修改driver table中自己的状态
In Summary
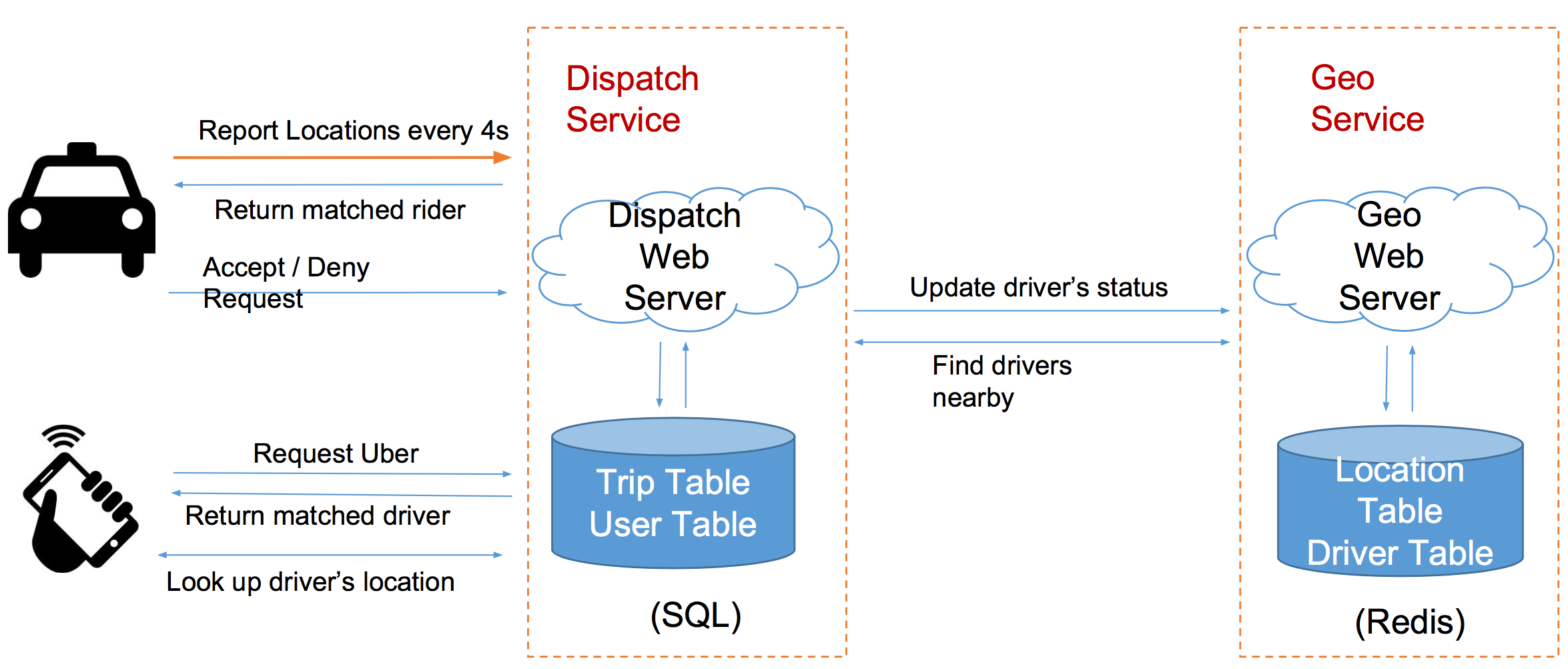
不常改的trip table和user table放在SQL 经常需要修改的Location Table和driver table放在redis
Scale
- DB Sharding
- 分摊流量
- 避免single point failure
sharding based on City
- why not user_id or geohash
- 因为Uber是City Based
- Geo Fence 用多边形代表城市的范围
- 变成几何问题,求一个点是否在多边形内
- 乘客在两个城市的边界
- 找到周围的2-3个城市,提前记录下来。汇总多个城市的查询结果,
- How to check rider is in Airport
- 分为两级Fence查询,先找到城市,再在城市中查询Airport Fence
How to reduce impact on db crash
- Replica by redis, master-slave
- Replica by yourself
- 底层存储的接口将每一份数据写3分,将sharding key从city_id扩展为123-0,123-1,123-2。读取的时候从任意一份replica里读取,读不到的时候,从另外一份读。
- 让更强大的NoSQL数据库帮你处理,Riak/Cassandra
- 既然用多台机器了,每台的流量就比较少了。而这类成熟的NoSQL数据库,能够帮你更好的处理Replica和机器挂掉之后恢复的问题。
- 此时col key是geohash, row key是city_id