4S 分析法
Scenario
- 哪些功能,需要多好
- Features/QPS/DAU/Interfaces
QPS
- Concurrent User
- DAU每个用户平均请求次数/一天多少秒 150M60/86400 ~100k
- 峰值Peak = Average Concurrent User * 3 ~ 300k
- Fast Growing product
- max peak user in 3 months = peak users * 2
- Read QPS
- 300k
Write QPS
- 5k
QPS
- 100
- 1k 考虑single point failure
- 1m 1k台web服务器的集群,考虑maintainance
- QPS和Web Server/Database之间的关系
- 一台web server承受量约为1k QPS,考虑到逻辑处理和数据库查询的瓶颈
- 一台SQL database承受量约为100 QPS,若JOIN和Index query比较多的话,会更小
- 一台NoSQL database(cassandra)可以承受约10k
- 一台NoSQL database(Memcached)可以承受约1M
Service
- 大系统拆分为小服务
Split/Application/Module
Twitter
- user service
- tweet service
- media service
- friendship service
Storage
- how to store and visit
- Schema/Data/SQL/NoSQL/File System
SQL Database
e.g, User table in Twitter
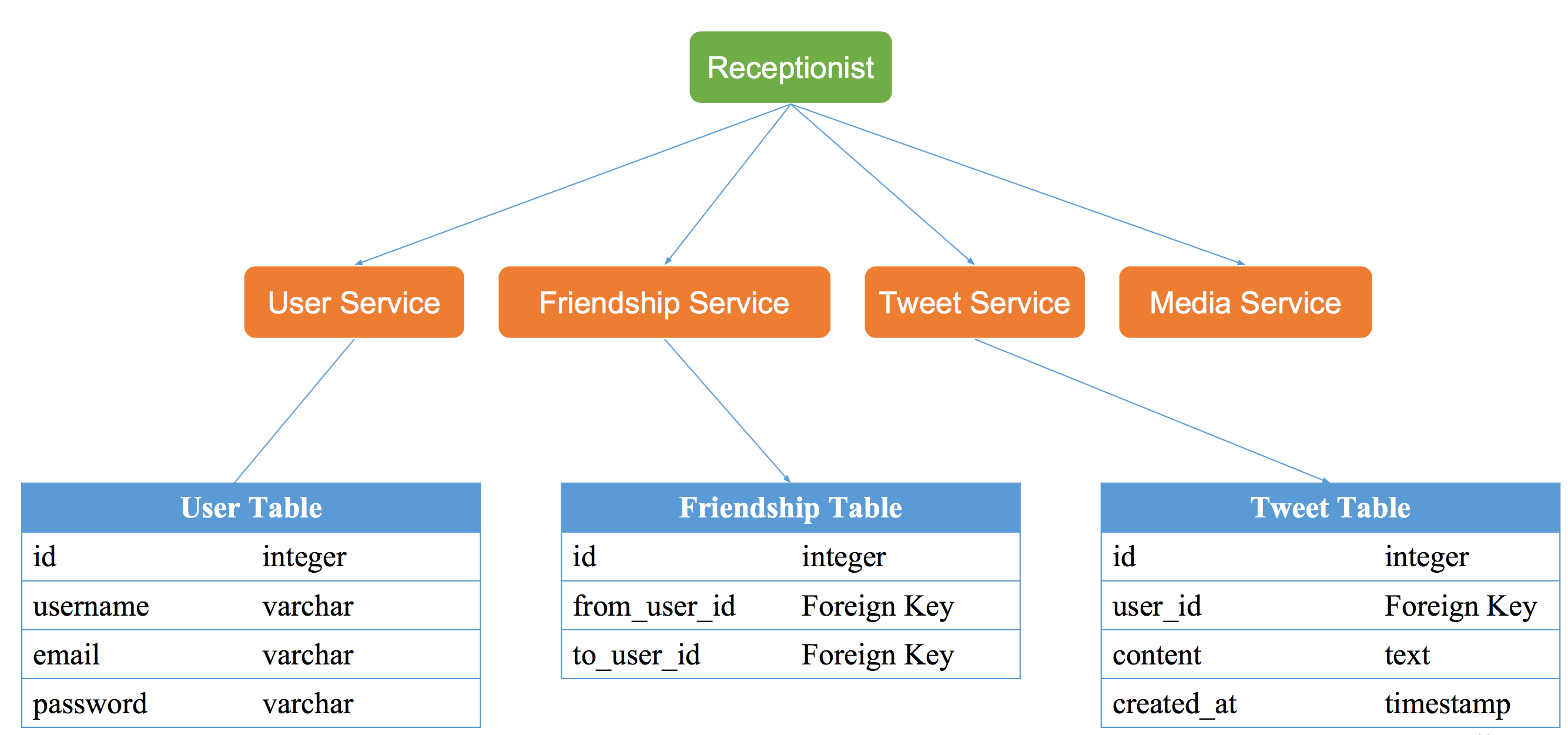
NoSQL database
e.g Tweets, Social Graph
File System
e.g Photos, files
Scale
- 解决缺陷,吹问题
- Robust/Maintaince/Scalability/Optimize
News Feed
Storage
Pull Model
- 算法
- 获取每个好友前100条Tweets,合并出前100条news feed (k路归并算法Merge k sorted Arrays)
- 复杂度分析
- New Feed: N个关注对象,则为N次DB reads + k路归并(可以忽略,主要考虑数据库的读取次数)
- post a tweet : 1 DB write
- 缺陷:
- 查询次数太多(虽然对user_id 有index,但是是对不同个的user)
- 而且DB发生在user request news feed的时候
Push Model
- 算法(Fanout)
- 为每一个用户建立一个list存储他的news feed信息。这里要理解,是有一个New Feed table(存的是发给谁,谁发的和发的内容),其中以owner_id为index,相同owner_id为这个user的list
- 用户post a tweet之后,将该推文逐个推送到每个用户的news feed list中
- 只需要从news feed list中读取最新的100条即可
- 复杂度分析
- News Fee: 1 DB read
- Post a tweet: N followers, N DB writes (async tasks serve)
- 缺陷
- table 可能会变得很大,以后需要shade&split。按照owner_id来做sharding
- (当你是大V的时候,有的粉丝有可能要很久以后才能收到消息的更新
- 可能存在大量重复数据,而且数据可能是非常分散在不同的系统里的
Async
适用于比较慢的操作,发送邮件重试等。需要一个Message Q,是一个producer consumer model
- Message Queue
- 一个先进先出的任务队列列表
- 所有做任务的woker进程共享一个列表
- wokers从列表中获得任务去做,做完之后反馈给队列服务器
- 队列服务器是做一部任务必须有的组成部分
Scale
Pull Model
瓶颈发生在用户read
- 在DB访问前加入Cache
- Cache每个用户的Timeline
- N DB read -> N cache read
- cache for how long?
- Cache每个用户的News Feed
- 不用每次都归并最近100条,只需要归并n个用户在某个timestamp之后的所有feed
Push Model
- Push模型将news feed存在disk里不需要担心存储资源
- Inactive users,rank followers by weight
- follower >> followings
- tradeoff: pull + push vs push
- 标记明星用户,对于明星用户,不push到news feed中,而取的时候直接从明星的timeline里取
- how to define starts?
- when starts lose followers
Choose between push vs pull
| push | pull | |
|---|---|---|
| 资源少,代码少 | 资源充足 | |
| 实时性低 | 实时性高 | |
| 发帖少 | 发帖多 | |
| 好友关系为双向 | 单项关系,明星问题 |
follow and unfollow
- follow之后,异步的将他的timeline合并到你的news feed中
- unfollow之后,异步的移除
- pros:似乎立刻follow成功
- cons:unfollow之后,可能还会看到他的信息
likes
不能在获取帖子的时候实时的计算like(SQL select count),
- De-normalize 用一个like table (comment table)保存like记录,每次有一条like记录创建,则在tweet table中直接更新like数量
Pagination
通常来说,翻页这个完全可以作为一道单独的系统设计面试题来问你。翻页并不是简单的1-100,101-200这样去翻页。因为当你在翻页的时候,你的news feed可能已经添加了新的 内容,这个时候你再去索引最新的101-200可能和你的1-100就有重叠了。
通常的做法是,拿第101个帖子的timestamp作为下一页的起始位置,也就是说,当用户在看到第一页的前100个帖子的时候,他还有第101个帖子的timestamp信息(隐藏在你看不到的地方),然后你请求下一页的时候,会带上这个timestamp的信息,server端会去数据库里请求 >= timestamp 的前101个帖子,然后也同样把第101个帖子作为下一页的timestamp。这个方法比直接用第100个帖子的timestamp好的地方是,你如果读不到第101个帖子,说明没有下一页了,如果你刚才只有100个帖子的话,用第100个帖子的timestamp的坏处是,你会有一次空翻。
Cache
类似于Hashmap,由key-value结构来取。保存在内存里,常用的包括Memcached和Redis 成本较高,断电会丢失数据