数据库系统
- 建立在文件系统之上
- 负责组织把一些数据存到文件系统
- 对外的接口比较方便操作数据
Scenario
- 查询:key(令狐冲+颜值)
- 返回:value (5)
Storage
不是存在表中,而是存在文件里例如json
查询
文件排序 对文件进行外排序,即把文件分成若干部分放到内存中排序好,后面进行k merge 在排序后,只需要对于文件进行二分查询
硬盘里的二分查询 每次把中间的那部分放到内存中进行比较
修改 - 当需要修改数据的时候
- 直接在文件里修改
- 修改的值占据更多空间,int->long
- 读取整个文件,修改好了,重新写入覆盖原来文件
- 太慢
- 不修改,直接append操作加在文件最后
- 通过timestamp来获取最新的
- 无法再用二分操作进行读取了。
- 过一段时间统一进行文件整理,整理成有序的,把outdated的文件定时删除
分块有序,读的时候仍然二分,写的时候append到最后
- 内部的每一块都是有序的
- 只有最后一块是无序的,在最后用一个for loop读取即可
- 同样还是可以根据external sort来把无序的变成有序的。可以配置一定的大小,到达后,进行排序。
- 可以把这一块以sorted list(skip list)的形式,保存在内存里,然后达到一定大小以后serialize to disk (sstable)
- 块可能有越来越多重复的值,需要进行定期的整理。通过k merged sorted整理成一个有序块,然后删掉outdate的数据
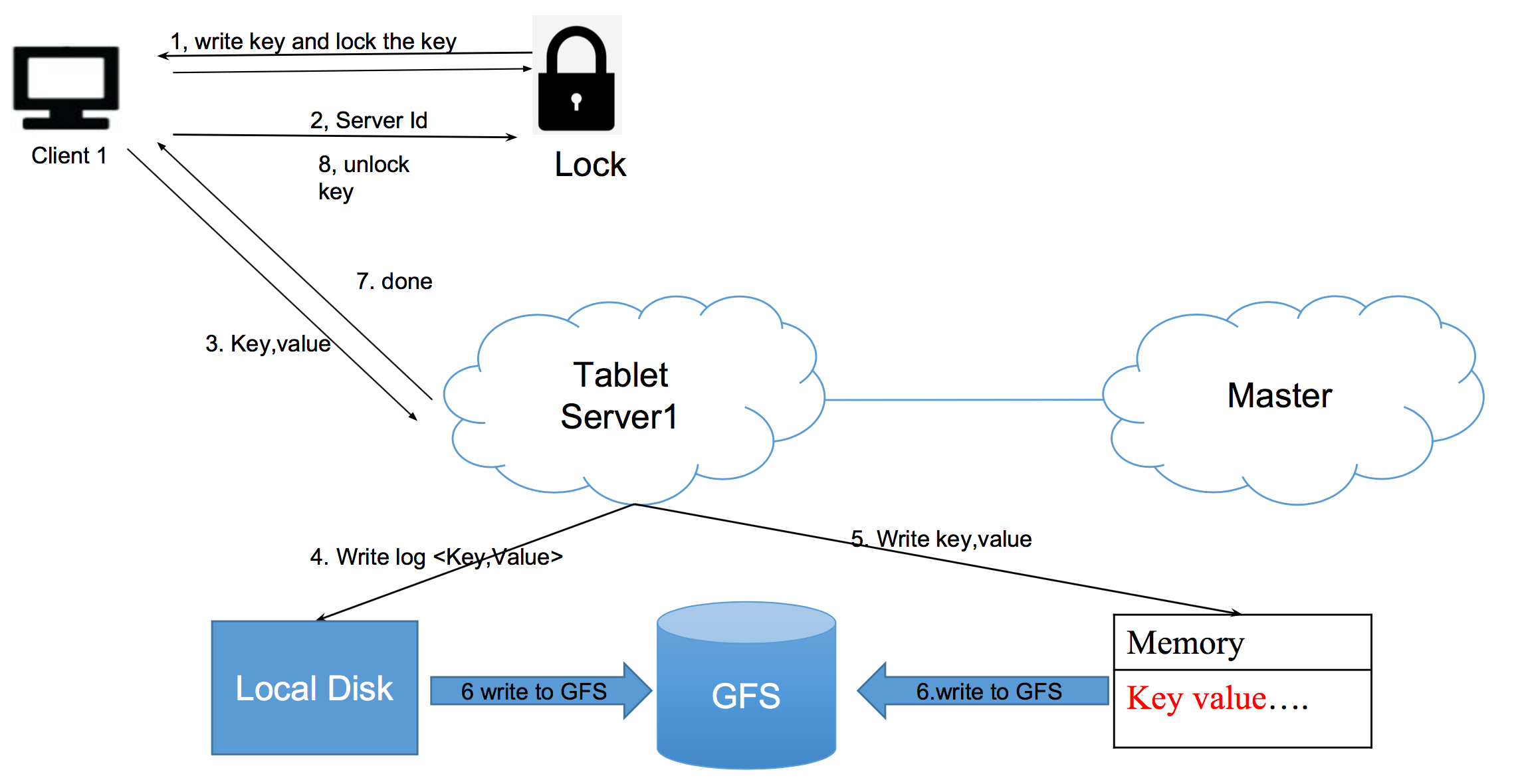
完整的写入过程
读入到内存快速排序 所有数据1次硬盘写入 + 1次硬盘统一读取 + 内存排序+1次硬盘写入
硬盘外部排序 不一定需要,可以用内存排序
一开始就可以直接存在内存里,所以只需要 内存排序 + 1次硬盘写入
持久化,如果机器挂了,内存没了
WAL Write Ahead Log,没电了以后可以通过log快速回复 WAL非常方便,不像重要数据需要整理。
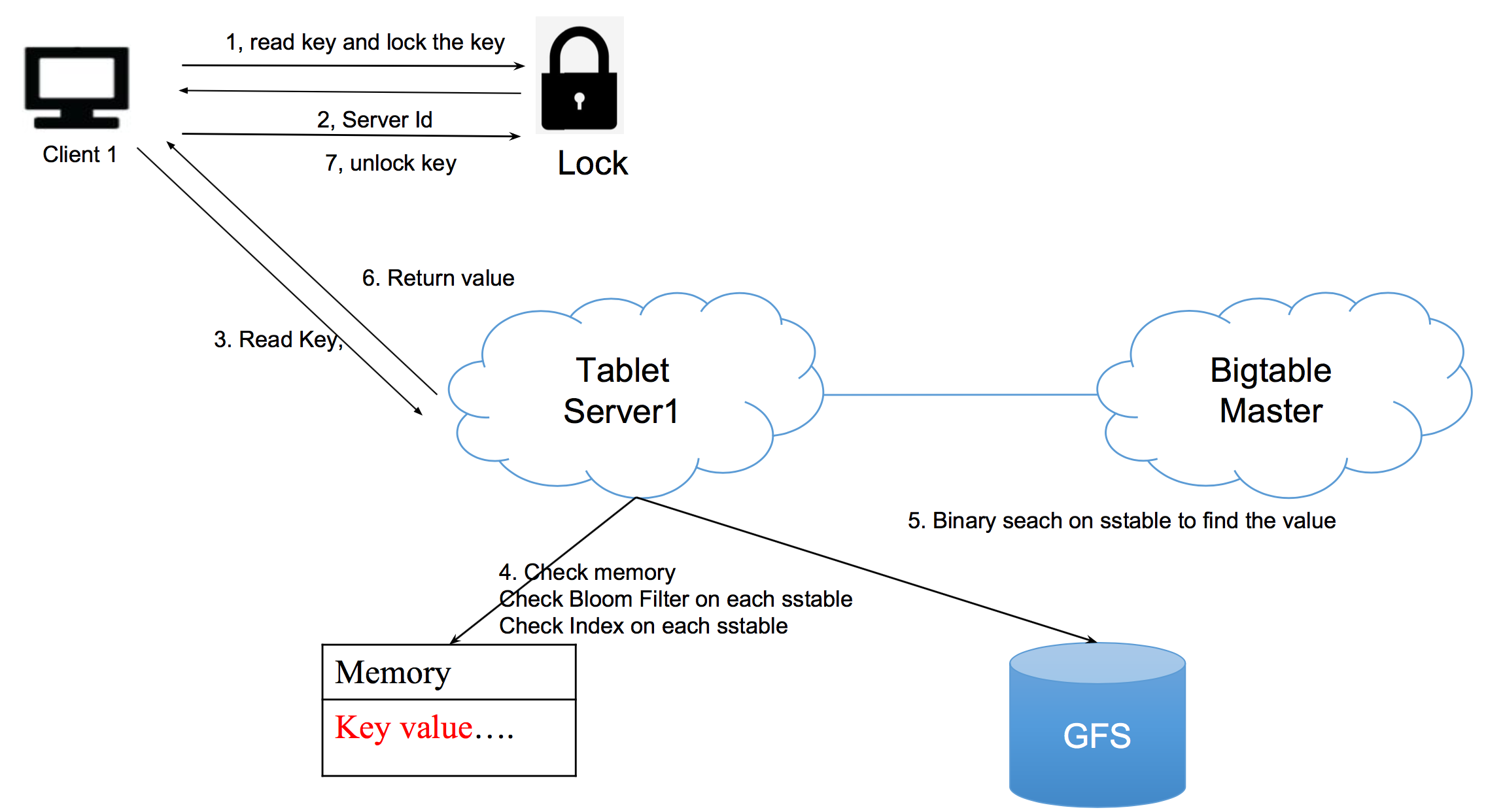
完整的读出的过程
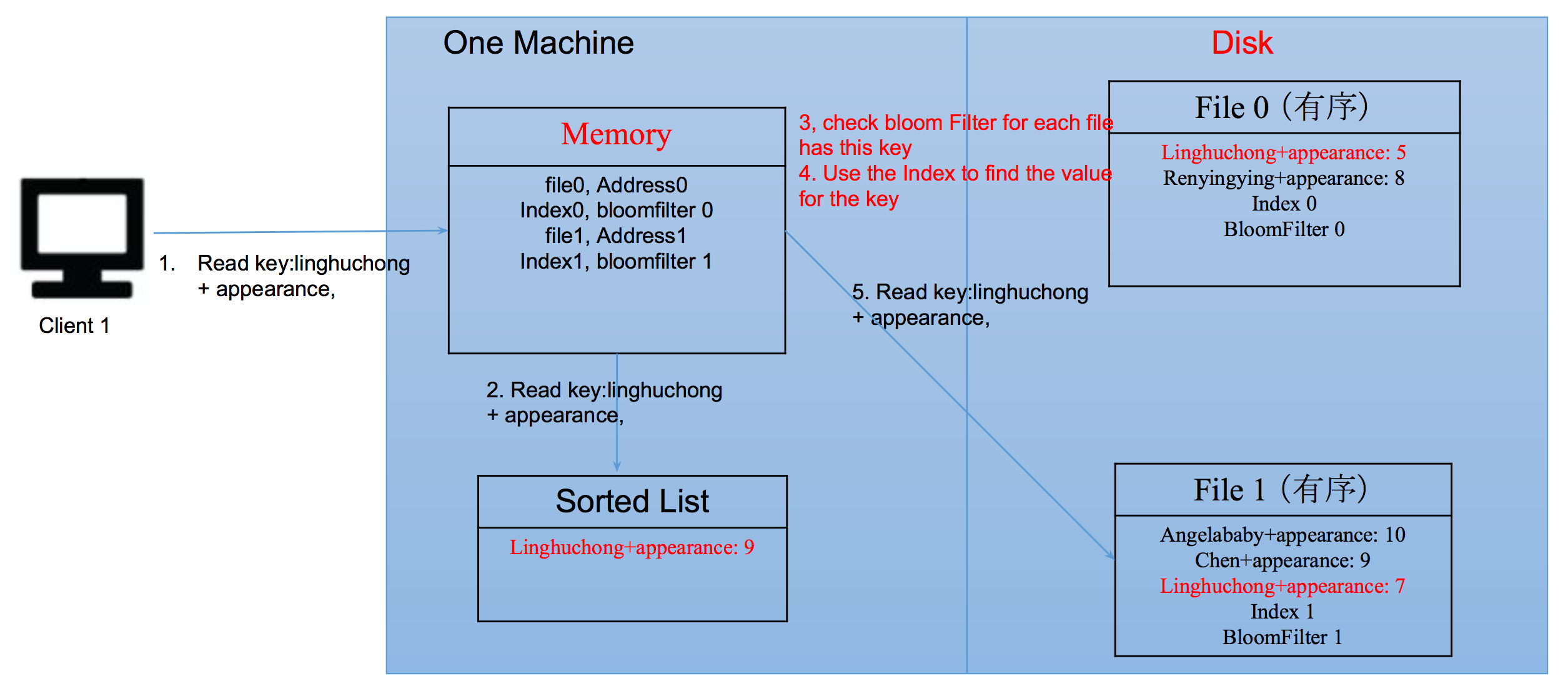
数据是在内存?file 0?file 1?
- 建立index,以减少磁盘的读写次数
- 不能直接以key建立索引,可以用key的首字母作为index的key,address作为value。这样的话,每次的binary search 范围就小的多了
- 如何检查一个key是否在一个file里
- Bloom Filter快速过滤掉错误的case,然后再用index去查询。因为BF远远快于内存
- 在每个file 0后,备份index和BF以防止内存丢失
Bloom Filter
可以用于检索一个元素是否在集合中,有很高的空间效率和查询时间,但是有一定的误识别率
Bloom Filter包含m位的位数组,每一位都置为0,并且包含k个hash函数(k远小于m),当一个元素加入集合时,通过k个hash函数将隔着 元素映射到m中的k个点,并把他们置为1。 (1) 如果经过k个hash函数映射到m的位置全部为1时,则元素可能存在 (2) 如果经过k个hash函数映射到m的位置至少有一个为0时,则元素一定不存在
hash函数越多,数组越长,误判率越小 加入的元素越多,误判率越大
Scale
Horizontal Sharding
row key is the name consistent hashing (row key)
Master-Slave
Master: consistent hash map, key:server address
How to read/write a key
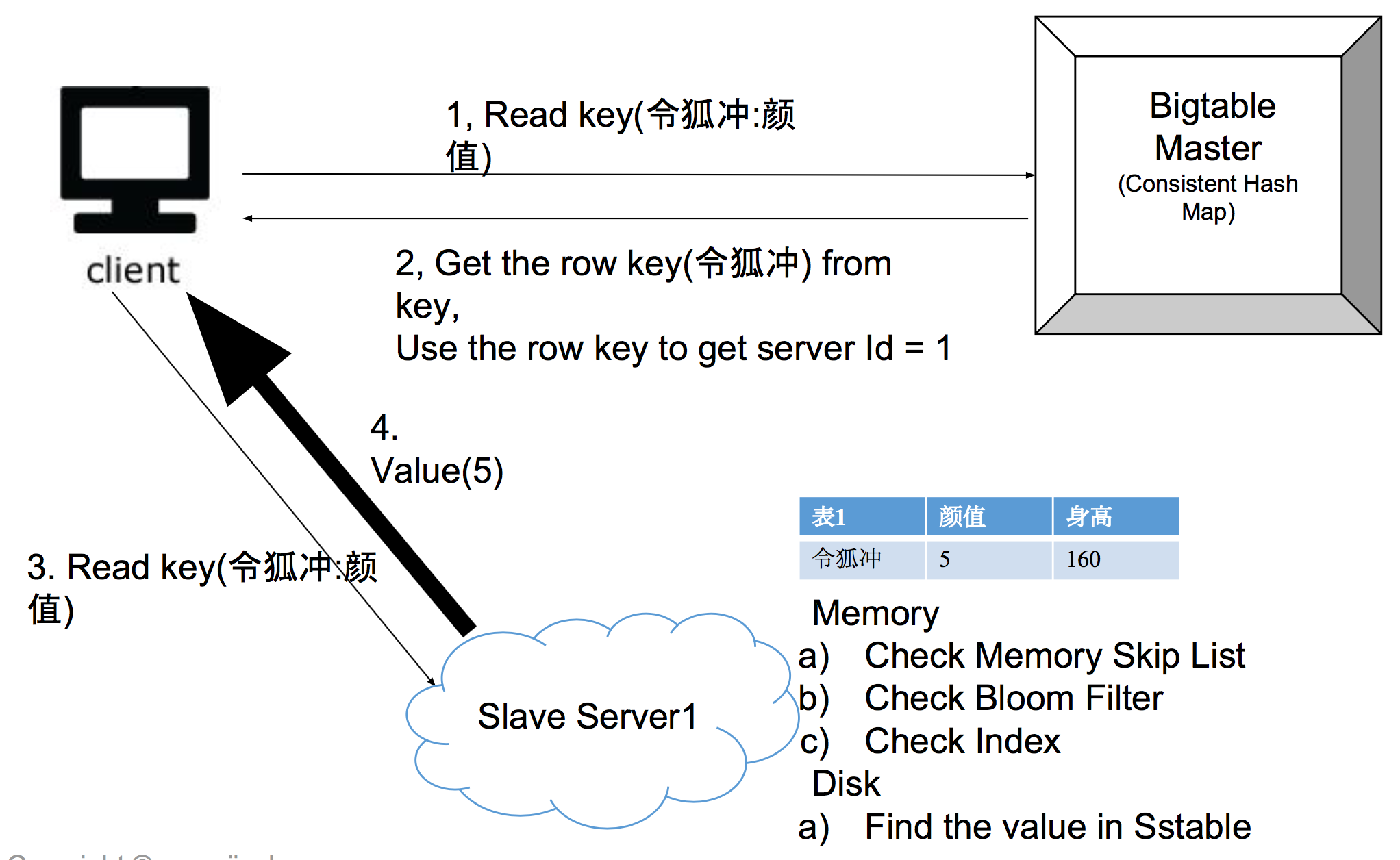
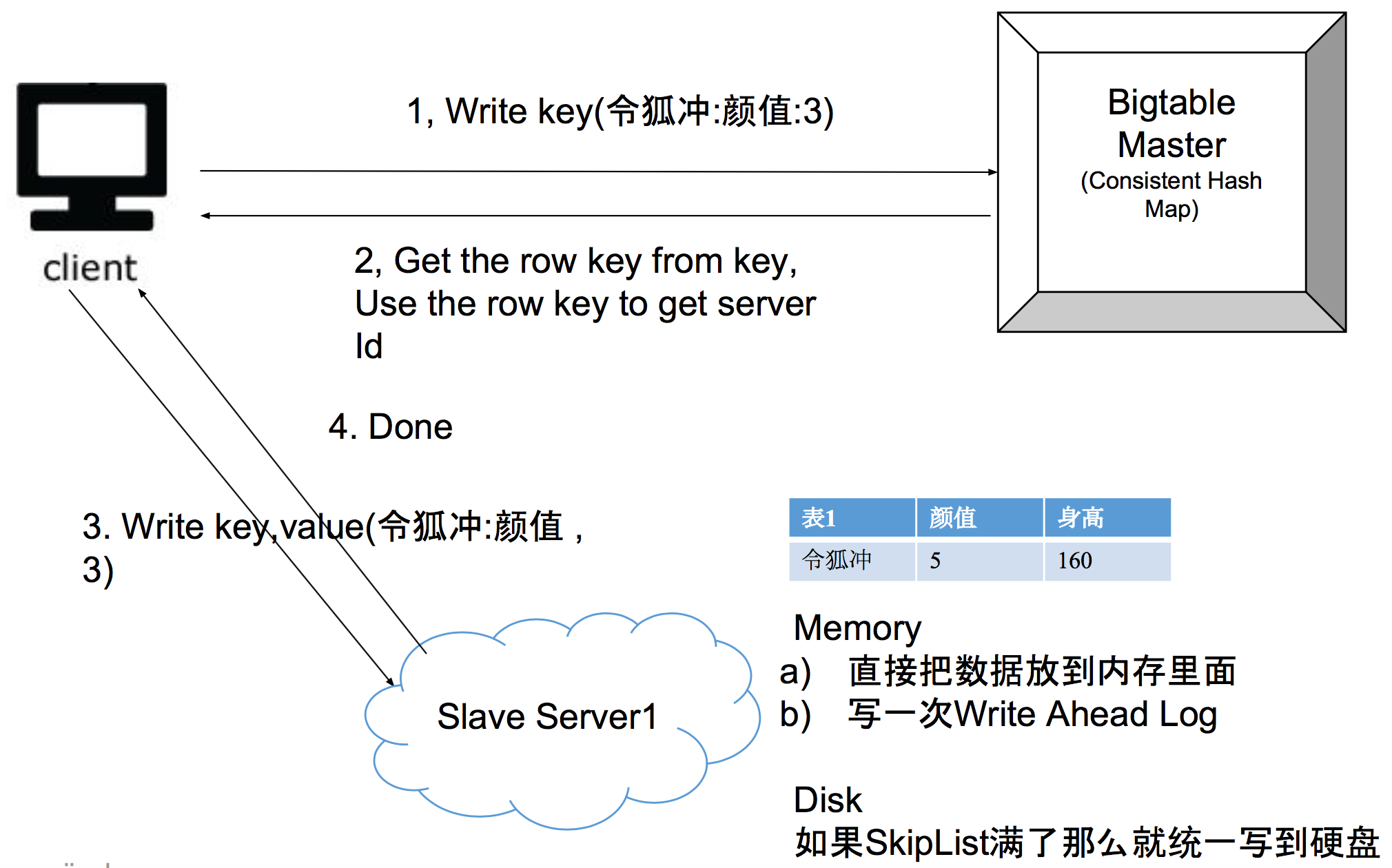
Data 存不下了
- 存到GFS,因为
- Disk size
- replica
- failure and recovery
- 仍然需要本地硬盘作为buffer
BigTable + GFS
- bigtable的存储单位是Sstable
- GFS读写的单位是chunk
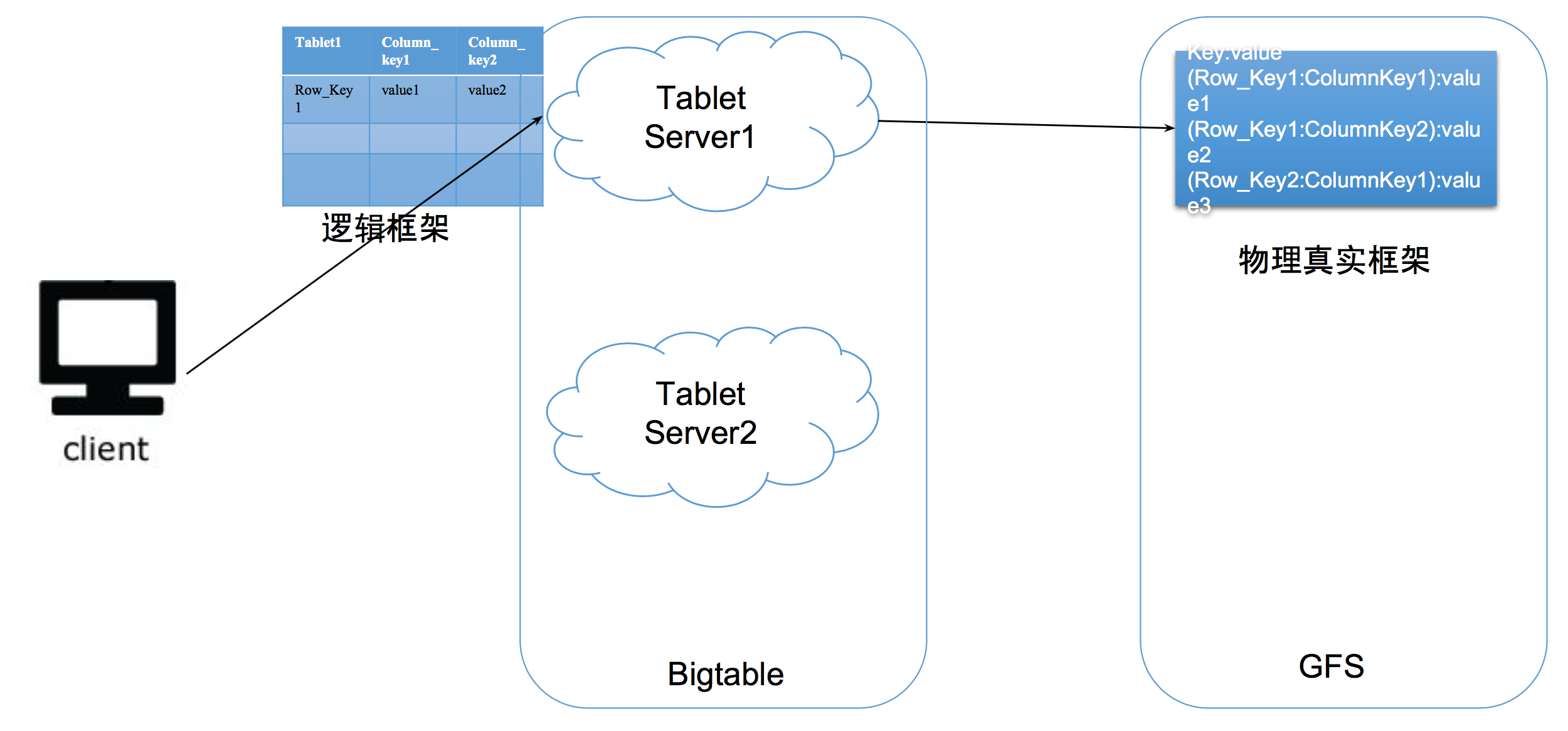
What if we read and write the same key at the same time
Race condition 把metadata直接保存在锁上,这样master也不需要再存一份了。
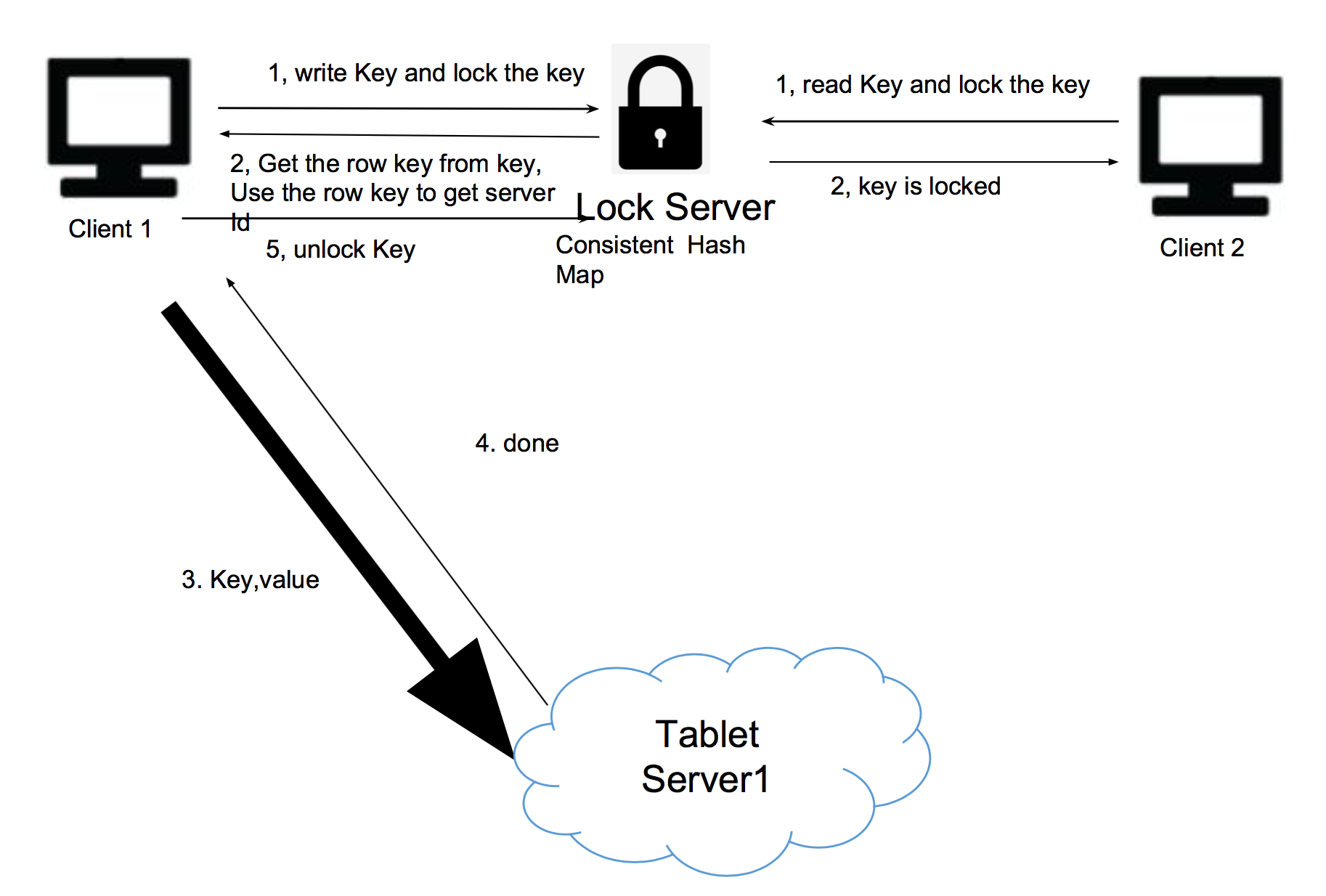
GFS不需要锁,因为GFS不被修改
In Summary
Design
- client + master + tablet + distributed lock
- client
- read and write
- tablet server
- maintain the data (key value pairs)
- master
- shard the file
- manage the servers health
- distributed lock
- update metadata
- maintain the metadata
- lock key